web网站开发程序员重庆森林为什么不能看
当读者需要获取到特定进程内的寄存器信息时,则需要在上述代码中进行完善,首先需要编写CREATE_PROCESS_DEBUG_EVENT事件,程序被首次加载进入内存时会被触发此事件,在该事件内首先我们通过lpStartAddress属性获取到当前程序的入口地址,并通过SuspendThread暂停程序的运行,当被暂停后则我没就可以通过ReadProcessMemory读取当前位置的一个字节机器码,目的是保存以便于后期的恢复,接着通过WriteProcessMemory向对端(void*)dwAddr地址写出一个0xCC断点,该断点则是int3停机指令,最后ResumeThread恢复这个线程的运行,此时程序中因存在断点,则会触发一个EXCEPTION_DEBUG_EVENT异常事件。
case CREATE_PROCESS_DEBUG_EVENT:
{// 获取入口地址 0x0 可以增加偏移到入口后任意位置DWORD dwAddr = 0x0 + (DWORD)de.u.CreateProcessInfo.lpStartAddress;// 暂停线程SuspendThread(de.u.CreateProcessInfo.hThread);// 读取入口地址处的字节码ReadProcessMemory(de.u.CreateProcessInfo.hProcess, (const void*)dwAddr, &bCode, sizeof(BYTE), &dwNum);// 在入口地址处写入 0xCC 即写入 INT 3 暂停进程执行WriteProcessMemory(de.u.CreateProcessInfo.hProcess, (void*)dwAddr, &bCC, sizeof(BYTE), &dwNum);// 恢复线程ResumeThread(de.u.CreateProcessInfo.hThread);break;
}
当异常断点被触发后,则下一步就会触发两次异常,第一次异常我们可以使用break直接跳过,因为此断点通常为系统断点,而第二次断点则是我们自己设置的int3断点,此时需要将该请求发送至OnException异常处理函数对其进行处理,在传递时需要给与&de调试事件,以及&bCode原始的机器码;
case EXCEPTION_DEBUG_EVENT:
{switch (dwCC_Count){// 第0次是系统断点,这里我们直接跳过case 0:dwCC_Count++; break;// 第1次断点,我们让他执行下面的函数case 1:OnException(&de, &bCode); dwCC_Count++; break;}
}
异常事件会被流转到OnException(DEBUG_EVENT* pDebug, BYTE* bCode)函数内,在本函数内我们首先通过使用OpenProcess/OpenThread两个函数得到当前进程的句柄信息,接着使用SuspendThread(hThread)暂时暂停进程内线程的执行,通过调用ReadProcessMemory得到线程上下文异常产生的首地址,当得到首地址后,则可以调用GetThreadContext(hThread, &context)得到当前线程的上下文,一旦上下文被获取到则读者即可通过context.的方式得到当前程序的所有寄存器信息,为了让程序正常执行当读取结束后,通过WriteProcessMemory我们将原始机器码写回到内存中,并SetThreadContext设置当前上下文,最后使用ResumeThread运行该线程;
void OnException(DEBUG_EVENT* pDebug, BYTE* bCode)
{CONTEXT context;DWORD dwNum;BYTE bTmp;HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, pDebug->dwProcessId);HANDLE hThread = OpenThread(THREAD_ALL_ACCESS, FALSE, pDebug->dwThreadId);// 暂停指定的线程SuspendThread(hThread);// 读取出异常首地址ReadProcessMemory(hProcess, pDebug->u.Exception.ExceptionRecord.ExceptionAddress, &bTmp, sizeof(BYTE), &dwNum);context.ContextFlags = CONTEXT_FULL;GetThreadContext(hThread, &context);printf("\n");printf("EAX = 0x%08X | EBX = 0x%08X | ECX = 0x%08X | EDX = 0x%08X \n",context.Eax, context.Ebx, context.Ecx, context.Edx);printf("EBP = 0x%08X | ESP = 0x%08X | ESI = 0x%08X | EDI = 0x%08X \n\n",context.Ebp, context.Esp, context.Esi, context.Edi);printf("EIP = 0x%08X | EFLAGS = 0x%08X\n\n", context.Eip, context.EFlags);// 将刚才的CC断点取消,也就是回写原始指令集WriteProcessMemory(hProcess, pDebug->u.Exception.ExceptionRecord.ExceptionAddress, bCode, sizeof(BYTE), &dwNum);context.Eip--;// 设置线程上下文SetThreadContext(hThread, &context);// printf("进程句柄: 0x%08X \n", pDebug->u.CreateProcessInfo.hProcess);// printf("主线程句柄: 0x%08X \n", pDebug->u.CreateProcessInfo.hThread);printf("虚拟入口点: 0x%08X \n", pDebug->u.CreateProcessInfo.lpBaseOfImage);// 恢复线程执行ResumeThread(hThread);CloseHandle(hThread);CloseHandle(hProcess);
}
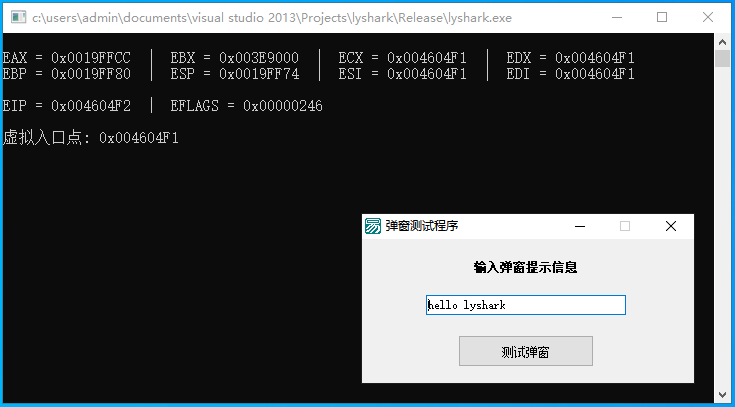
当这段程序被运行后,读者可看到如下图所示的输出信息,该进程中当前寄存器的状态基本上都可以被获取到;
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/94ad4ba.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!